


Code defects are not planned; they are accidents that result from an inability to understand execution flow under different input conditions.
But just as airbags are the last line of defense in a car, a debugger should be the last line of defense for a programmer. Defensive driving reduces or eliminates reliance on airbags. Defensive driving is proactive, it is using all available data to predict and avoid problems.

Situations exist where hardware and software debuggers are essential and have no substitutes. But most of the time the debugger is not the best tool to find and remove defects.
 Debuggers will not fix the
defect for you.
Debuggers will not fix the
defect for you. Debuggers are not like washing machines where you can throw in your code and some soap, go get some coffee and watch TV, and then 30 minutes later the defect is removed.
You can only fix a defect when you understand the root cause of the problem.
Remember, removing a defect does not advance your project; your project will be on hold until you resolve the problem. You are better served by making sure the defect never gets into your code rather than learning to become efficient at getting rid of them.
Inspiration, not Perspiration
A defect is an observation of program behavior that deviates from a specific requirement (no requirements = no defect :-) ). A developer familiar with the code pathways can find defects by simply reasoning about how the observation could arise.
The nature of mainframes in university was that you would queue up at the high speed printer with the 10—15 other people all waiting for their print-outs.

The lesson learned was that the ability to think is critical to finding defects.
There is no substitute for the ability to reason through a defect; however, you will accelerate the process of finding defects if you lay down code pathways as simply as possible. In addition, if there are convoluted sections of code you will benefit by rewriting them, especially if they were written by someone else.
Not There When You Want Them
Even if you think the debugger is the best invention since sliced bread most of us can't use a debugger on a customer's production environments. There are so many production environments that are closed
off behind firewalls on computers with minimal O/S infrastructure. Most
customers are not going to let you mess around with their production
environments and it would take an act of god to get the debugger
symbolic information on those computers.
There are so many production environments that are closed
off behind firewalls on computers with minimal O/S infrastructure. Most
customers are not going to let you mess around with their production
environments and it would take an act of god to get the debugger
symbolic information on those computers.In those environments the typical solution is to use a good logging system (i.e. Log4J, etc). The placement of the logging calls will be at the same locations that you would throw exceptions – but since this is a discussion of debuggers and not debugging we will discuss logging at another time.
Debuggers and Phantom Problems

Our performance in development was quite slow and I suspected that our code files with symbolic information were potentially the source of the problem. I started compiling the program without the symbolic information to see if we could get a performance boost.
To my surprise, not only did we get a performance boost but the random crashes vanished. With further investigation we discovered that the symbolic information for the debugger was taking up so much RAM that it was causing memory overflows.
Debuggers and Productivity

 Research
in developer productivity has show that the most productive developers
are at least 10x faster than everyone else.
Research
in developer productivity has show that the most productive developers
are at least 10x faster than everyone else. If you work with a hyper-productive individual then ask them how much time they spend in the debugger, odds are they don't...

Charlie came back as a consultant; he walked around the system for a few minutes then took out some chalk and made an X on a part (he correctly identified the malfunctioning part).
Charlie then submitted a $10,000 bill to GE, who was taken aback by the size of the bill (about $300,000 today). GE asked for an itemized invoice for the consultation and Charles sent back the following invoice:
Making the chalk mark $1
Knowing where to place it $9999
Debuggers are Distracting
As Brian W. Kernighan and Rob Pike put it in their excellent book “The Practice of Programming”As personal choice, we tend not to use debuggers beyond getting a stack trace or the value of a variable or two. One reason is that it is easy to get lost in details of complicated data structures and control flow; we find stepping through a program less productive than thinking harder and adding output statements and self-checking code at critical places. Clicking over statements takes longer than scanning the output of judiciously-placed displays. It takes less time to decide where to put print statements than to single-step to the critical section of code, even assuming we know where that is. More important, debugging statements stay with the program; debugging sessions are transient.
A debugger is like the Sirens of Greek mythology, it is
very easy to get mesmerized and distracted by all the data being
displayed by the debugger.

Despite a modern debugger’s ability to show an impressive amount of context at the point of execution, it is just a snap shot of a very small portion of the code. It is like trying to get an image of a painting where you can only see a small window at a time. Above we show 6 snapshots of a picture over time and it is hard to see the big picture.
 The above snap shots are small windows on the Mona Lisa,
but it is hard to see the bigger picture from small snap shots. To
debug a problem efficiently you need to have a higher level view of the picture
to assess what is going on (effectiveness).
The above snap shots are small windows on the Mona Lisa,
but it is hard to see the bigger picture from small snap shots. To
debug a problem efficiently you need to have a higher level view of the picture
to assess what is going on (effectiveness).
If you have to find defects in code that you have not written then you will still be better off analyzing the overall structure of the code (modules, objects, etc) than simply single-stepping through code in a debugger hoping to get lucky.
 Defects occur when we have
not accounted for all the behavioral pathways that will be taken through the
code relative to all the possible data combinations of the variables.
Defects occur when we have
not accounted for all the behavioral pathways that will be taken through the
code relative to all the possible data combinations of the variables.
Some common defects categories include:
 The same way that we have defensive driving there is the
concept of defensive programming, i.e. “The best
defense is a good offense”.
The same way that we have defensive driving there is the
concept of defensive programming, i.e. “The best
defense is a good offense”.
My definition of defensive programming is to use techniques to construct the code so that the pathways are simple and easy to understand. Put your effort into writing defect free code, not on debugging code with defects.
In addition, if I can make the program aware of its context when a problem occurs then it should halt and prompt me with an error message so that I know exactly what happened.
There are far too many defensive programming techniques to cover them all here, so let's hit just a few that I like (send me your favorite techniques email ):
 One poor way to design a code pathway is the following
comment:
One poor way to design a code pathway is the following
comment:
// Program should not get here
Any developer who writes a comment like this should be shot. After all, what if you are wrong and the program really gets there? This situation exists in most programs especially for the default case of a case/switch statement.
Your comment is not going to stop the program and it will probably go on to create a defect or side effect somewhere else.
It could take you a long time to figure out what the root cause of the eventual defect; especially since you may be thrown off by your own comment and not consider the possibility of the code getting to that point.
Of course you should at least log the event, but this article is about debuggers and not debugging – so let’s leave the discussion about logging until the end of the article.
At a minimum you should replace the comment with the following:
throw new Exception( “Program should not get here!”);
Assuming that you have access to exceptions. But even this is not going far enough; after all, you have information about the conditions that must be true to get to that location. The exception should reflect those conditions so that you understand immediately what happened if you see it.
For example, if the only way to get to that place in the code is because the Customer object is inconsistent then the following is better:
throw new InconsistentCustomerException( “New event date preceeds creation date for Customer ” + Customer.getIdentity() );
If the InconsistentCustomerException is ever thrown then you will probably have enough information to fix the defect as soon as you see it.
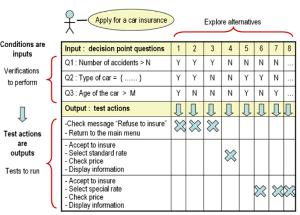 When you have complex sections of code with multiple
pathways then create a decision
table to help you to plan the code.
When you have complex sections of code with multiple
pathways then create a decision
table to help you to plan the code.
Decision tables have been around since the 1960s, they are one of the best methods for pro-actively designing sections of code that are based on complex decisions.
However, don't include the decision table in a comment unless you plan to keep it up to date (See Comments are for Losers).
 The pre-conditions are checked on the entry to the function
and the post-conditions are checked on the exit to the function. If any of the
conditions are violated then you would throw an exception.
The pre-conditions are checked on the entry to the function
and the post-conditions are checked on the exit to the function. If any of the
conditions are violated then you would throw an exception.
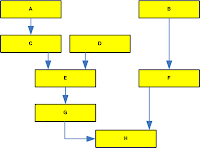
DbC is invasive and adds overhead to every call in your program. Let's see what can make this overhead worth it. When we write programs, the call stack can be quite deep.
Let's assume we have the following call structure; as you can see H can be reached through different call paths (i.e. through anyone calling F or G).
 Let's assume that the call flow from A has a defect
that needs to be fixed in H, clearly that will affect the call flow from
B.
Let's assume that the call flow from A has a defect
that needs to be fixed in H, clearly that will affect the call flow from
B.
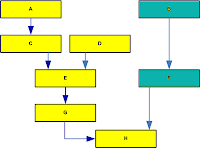
If the fix to H will cause a side effect to occur in F, then odds are the DbC post conditions of F (or B) will catch the problem and throw an exception.
Contrast this with fixing a problem with no checks and balances. The side effect could manifest pretty far away from the problem was created and cause intermittent problems that are very hard to track down.
Some of these exceptions do not happen very often because it will involve less than perfect input data – do you really want those exceptions to happen for the first time on a remote customer system for which you have few troubleshooting tools?
 If you are using Test Driven Development
(TDD) then you already have a series of unit tests for all your code.
The idea is good, but does not go far enough in my opinion.
If you are using Test Driven Development
(TDD) then you already have a series of unit tests for all your code.
The idea is good, but does not go far enough in my opinion.
Automated tests should not only perform unit tests but also perform tests at the integration level. This will not only test your code with unusual conditions at the class level but also at the integration level between classes and modules. Ultimately these tests should be augmented with the use of a canonical database where you can test data side effects as well.
The idea is to build up your automated tests until the code coverage gets in the 80%+ category. Getting to 80%+ means that your knowledge of the system pathways will be very good and the time required for defect fixing should fall dramatically.
Why 80%+? (See Minimum Acceptable Code Coverage)
If you can get to 80%+ it also means that you have a pretty good understanding of your code pathways. The advantage to code coverage testing is that it does not affect the runtime performance of your code and it improves your understanding of the code.
All your defects are hiding in the code that you don't test.
The only way to resolve a defect is by understanding what is happening in your code. So the next time you have a defect to chase down, start by thinking about the problem. Spend a few minutes and see if you can't resolve the issue before loading up the debugger.
Another technique is to discuss the source of a defect with another developer. Even if they are not familiar with your code they will prompt you with questions that will quite often help you to locate the source of the defect without resorting to the debugger.
In several companies I convinced the developers to forgo using their debuggers for a month. We actually deleted the code for the debuggers on everyones system. This drastic action had the effect of forcing the developers to think about how defects were caused. Developers complained for about 2 weeks, but within the month their average time to find a defect had fallen over 50%.
Try to go a week without your debugger, what have you got to lose?
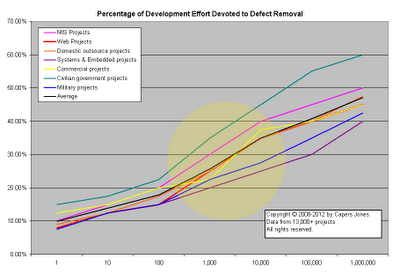
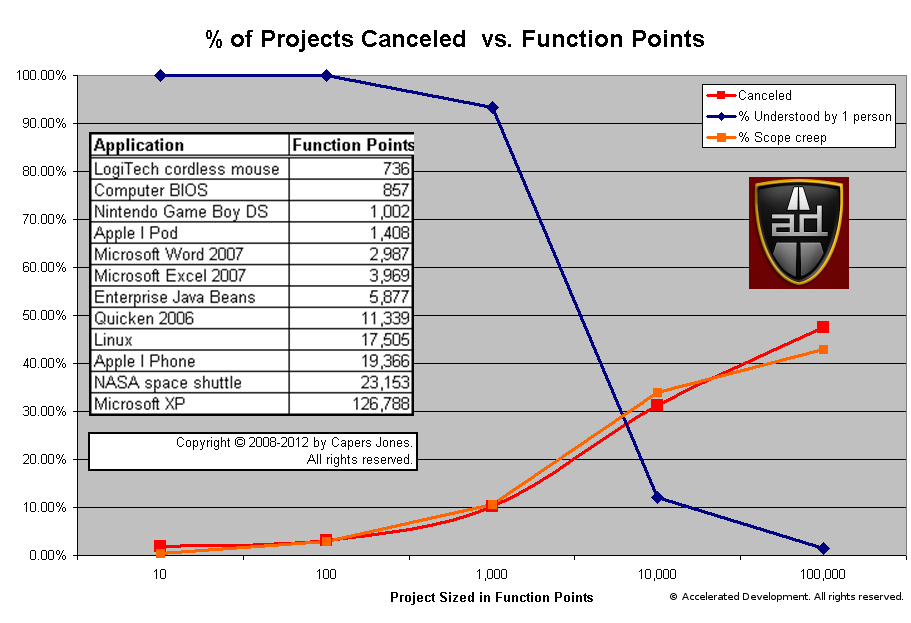
After all, the next graph shows how much effort we spend trying to remove defects, the average project ends up spending 30% of the total time devoted to defect removal. Imagine what a 50% boost in efficiency will do for your project? The yellow zone sketches out where most projects fall.
 There will definitely be times where a debugger will
be the best solution to finding a problem. While you are spending time in the debugger your project is on hold, it will not progress.
There will definitely be times where a debugger will
be the best solution to finding a problem. While you are spending time in the debugger your project is on hold, it will not progress.
Some programs have complex and convoluted sections that generate many defects. Instead of running through the sections with the debugger you should perform a higher level analysis of the code and rewrite the problematic section.
If you find yourself going down the same code pathways multiple times in the debugger then you might want to stop and ask yourself, "Is there a better way to do this?"
As Master Card might say, "Not using the debugger... priceless".
Want to see more sacred cows get tipped? Check out:

Despite a modern debugger’s ability to show an impressive amount of context at the point of execution, it is just a snap shot of a very small portion of the code. It is like trying to get an image of a painting where you can only see a small window at a time. Above we show 6 snapshots of a picture over time and it is hard to see the big picture.
The above snap shots are small windows on the Mona Lisa,
but it is hard to see the bigger picture from small snap shots. To
debug a problem efficiently you need to have a higher level view of the picture
to assess what is going on (effectiveness).If you have to find defects in code that you have not written then you will still be better off analyzing the overall structure of the code (modules, objects, etc) than simply single-stepping through code in a debugger hoping to get lucky.

Some common defects categories include:
- Uninitialized data or missing resources (i.e. file not found)
- Improper design of code pathways
- Calculation errors
- Improper persistent data adjustment (i.e. missing data)
The point is that there are really only a few ways that
defects behave. If you understand those common behaviors then you can structure
your code to minimize the chances of them happening.
Defensive Programming
My definition of defensive programming is to use techniques to construct the code so that the pathways are simple and easy to understand. Put your effort into writing defect free code, not on debugging code with defects.
In addition, if I can make the program aware of its context when a problem occurs then it should halt and prompt me with an error message so that I know exactly what happened.
There are far too many defensive programming techniques to cover them all here, so let's hit just a few that I like (send me your favorite techniques email ):
- Proper use of exceptions
- Decision Tables
- Design by contract
- Automated tests
Proper Use of Exceptions
One poor way to design a code pathway is the following
comment:// Program should not get here
Any developer who writes a comment like this should be shot. After all, what if you are wrong and the program really gets there? This situation exists in most programs especially for the default case of a case/switch statement.
Your comment is not going to stop the program and it will probably go on to create a defect or side effect somewhere else.
It could take you a long time to figure out what the root cause of the eventual defect; especially since you may be thrown off by your own comment and not consider the possibility of the code getting to that point.
Of course you should at least log the event, but this article is about debuggers and not debugging – so let’s leave the discussion about logging until the end of the article.
At a minimum you should replace the comment with the following:
throw new Exception( “Program should not get here!”);
Assuming that you have access to exceptions. But even this is not going far enough; after all, you have information about the conditions that must be true to get to that location. The exception should reflect those conditions so that you understand immediately what happened if you see it.
For example, if the only way to get to that place in the code is because the Customer object is inconsistent then the following is better:
throw new InconsistentCustomerException( “New event date preceeds creation date for Customer ” + Customer.getIdentity() );
If the InconsistentCustomerException is ever thrown then you will probably have enough information to fix the defect as soon as you see it.
Decision Tables
Improper design of code pathways has other incarnations, such as not planning enough code pathways in complex logic. i.e. you build code with 7 code pathways but you really need 8 pathways to handle all inputs. Any data that requires the missing 8th pathway will turn into a calculation error or improper persistent data adjustment and cause a problem somewhere else in the code.Decision tables have been around since the 1960s, they are one of the best methods for pro-actively designing sections of code that are based on complex decisions.
However, don't include the decision table in a comment unless you plan to keep it up to date (See Comments are for Losers).
Design by Contract
The concept of design by contract (DbC) was introduced in 1986 by the Eiffel programming language. I realize that few people program in Eiffel, but the concept can be applied to any language. The basic idea is that every class function should have pre-conditions and post-conditions that are tested on every execution.
DbC is invasive and adds overhead to every call in your program. Let's see what can make this overhead worth it. When we write programs, the call stack can be quite deep.
Let's assume we have the following call structure; as you can see H can be reached through different call paths (i.e. through anyone calling F or G).

If the fix to H will cause a side effect to occur in F, then odds are the DbC post conditions of F (or B) will catch the problem and throw an exception.
Contrast this with fixing a problem with no checks and balances. The side effect could manifest pretty far away from the problem was created and cause intermittent problems that are very hard to track down.
DbC via Aspect Oriented Programming
Clearly very few of us program in Eiffel. If you have access to Aspect Oriented Programming (AOP) then you can implement DbC via AOP. Today there are AOP implementations as a language extension or as a library for many current languages (Java, .NET, C++, PHP, Perl, Python, Ruby, etc).Automated Tests
Normal application use will exercise few code pathways in day to day application use. For every normal code pathway there will be several alternative pathways to handle exceptional processing, and this is where most defects will be found.Some of these exceptions do not happen very often because it will involve less than perfect input data – do you really want those exceptions to happen for the first time on a remote customer system for which you have few troubleshooting tools?
Automated tests should not only perform unit tests but also perform tests at the integration level. This will not only test your code with unusual conditions at the class level but also at the integration level between classes and modules. Ultimately these tests should be augmented with the use of a canonical database where you can test data side effects as well.
The idea is to build up your automated tests until the code coverage gets in the 80%+ category. Getting to 80%+ means that your knowledge of the system pathways will be very good and the time required for defect fixing should fall dramatically.
Why 80%+? (See Minimum Acceptable Code Coverage)
If you can get to 80%+ it also means that you have a pretty good understanding of your code pathways. The advantage to code coverage testing is that it does not affect the runtime performance of your code and it improves your understanding of the code.
All your defects are hiding in the code that you don't test.
Reducing Dependence on Debuggers
If you have to resort to a debugger to find a defect then take a few minutes after you solve the problem and ask, "Was there a faster way?". What did you learn from using the debugger? Is there something that you can do to prevent you (or someone else) having to use the debugger down this same path again? Would refactoring the code or putting in a better exception help?The only way to resolve a defect is by understanding what is happening in your code. So the next time you have a defect to chase down, start by thinking about the problem. Spend a few minutes and see if you can't resolve the issue before loading up the debugger.
Another technique is to discuss the source of a defect with another developer. Even if they are not familiar with your code they will prompt you with questions that will quite often help you to locate the source of the defect without resorting to the debugger.
In several companies I convinced the developers to forgo using their debuggers for a month. We actually deleted the code for the debuggers on everyones system. This drastic action had the effect of forcing the developers to think about how defects were caused. Developers complained for about 2 weeks, but within the month their average time to find a defect had fallen over 50%.
Try to go a week without your debugger, what have you got to lose?
After all, the next graph shows how much effort we spend trying to remove defects, the average project ends up spending 30% of the total time devoted to defect removal. Imagine what a 50% boost in efficiency will do for your project? The yellow zone sketches out where most projects fall.

| Function Points | Average Effort |
| 10 | 1 man month |
| 100 | 7 man month |
| 1000 | 84 man month |
| 10000 | 225 man year |
Conclusion
There will definitely be times where a debugger will
be the best solution to finding a problem. While you are spending time in the debugger your project is on hold, it will not progress.Some programs have complex and convoluted sections that generate many defects. Instead of running through the sections with the debugger you should perform a higher level analysis of the code and rewrite the problematic section.
If you find yourself going down the same code pathways multiple times in the debugger then you might want to stop and ask yourself, "Is there a better way to do this?"
As Master Card might say, "Not using the debugger... priceless".
 |
| Moo? |



















 ).
).
{kind=link}
{kind=link}